Le domaine Order to cash
- Olivier Jauze
- Case studies
- 4 juillet 2021
Table des matières
Contexte et historique
Il y a plusieurs années, nous avons repensé notre système d’information supportant les processus « order to cash » (de la commande à l’encaissement). À l’époque, nous utilisions un monolithe legacy (hébergé sur un mainframe) couvrant la majorité de ces processus. Nous avons choisi une approche best of breed : plusieurs solutions spécialisées ont été mises en œuvre pour couvrir les différentes étapes du processus, de la prise de commande à l’optimisation du transport jusqu’à la livraison logistique…
Ce changement nous a permis de :
- sélectionner les meilleurs logiciels pour chaque sous-processus ;
- amorcer le découplage du monolithe, permettant d’adapter nos processus à des rythmes de changement différents.
Dès lors que plusieurs systèmes contribuent à un même processus, un composant central devient nécessaire pour assurer l’exécution globale. Dans notre cas, c’était un orchestrateur central (outil de gestion de processus métier). Il dirigeait l’exécution des processus, tout en gérant la granularité des objets manipulés — ce qui n’est pas anodin. En effet, nous ne manipulons pas les mêmes objets tout au long du processus. Une commande client peut comporter 3 lignes, dont l’une sera divisée pour optimiser le transport (deux chargements différents, par exemple).
Dernier point : cet orchestrateur a été introduit aussi parce que les équipes en charge des applications contributrices ne savaient plus quelles règles métier implémenter. D’où la création d’une équipe dédiée à l’orchestrateur, chargée d’imposer ces règles.
Avec le temps, plusieurs problèmes sont apparus :
- L’orchestrateur est devenu un point de défaillance unique. En cas de panne, les livraisons clients étaient directement impactées.
- Il s’est transformé en monolithe difficile à maintenir. Environ 20 processus y étaient déployés, certains devenant impossibles à modifier sans tout re-tester.
Notre démarche
Nous avons donc décidé de repenser notre architecture autour des événements et de leur chorégraphie, avec pour objectif de nous débarrasser de l’orchestrateur. Voici comment nous avons procédé. Ce que nous décrivons ici est une recette — à adapter selon vos goûts !
Comme vous vous en doutez, nous avons utilisé Domain Driven Design (DDD) pour cette refonte. Il existe plusieurs manières de pratiquer le DDD, selon votre point de départ, vos assets, etc. Voici les étapes que nous avons suivies.
Tout commence par les frontières du domaine
Le domaine concerné est celui de l’Order to Cash. Il s’étend de la prise de commande jusqu’au paiement de la facture. Le groupe de travail a pris une hypothèse : les processus liés à la disponibilité des produits et à l’allocation des stocks sont hors périmètre — ils relèvent d’autres domaines avec lesquels nous interagissons.
Un event storming pour découvrir le domaine par les événements métiers
L’event storming est une pratique souvent utile pour découvrir un domaine. Dans notre cas, nous avons vite orienté l’exercice vers les informations échangées tout au long du processus. Cela a permis de mettre en lumière :
- La granularité des objets manipulés à chaque étape ;
- La temporalité des événements.
Quelques exemples :
- La ligne de commande client n’est pas celle que nous exécutons : elle peut être fractionnée ou réduite selon la disponibilité des produits et les dates de livraison possibles.
- Une livraison regroupe plusieurs lignes de commande, expédiées depuis le même entrepôt, avec un engagement de date.
- La réception chez le client se fait au niveau du camion, qui peut contenir plusieurs lignes de livraison.
- Une facture client regroupe plusieurs lignes de livraison avec les mêmes conditions de paiement.
- Un paiement regroupe plusieurs factures (partielles ou complètes) à une même échéance.
La figure ci-dessous illustre les objets manipulés, leur granularité et leurs relations :
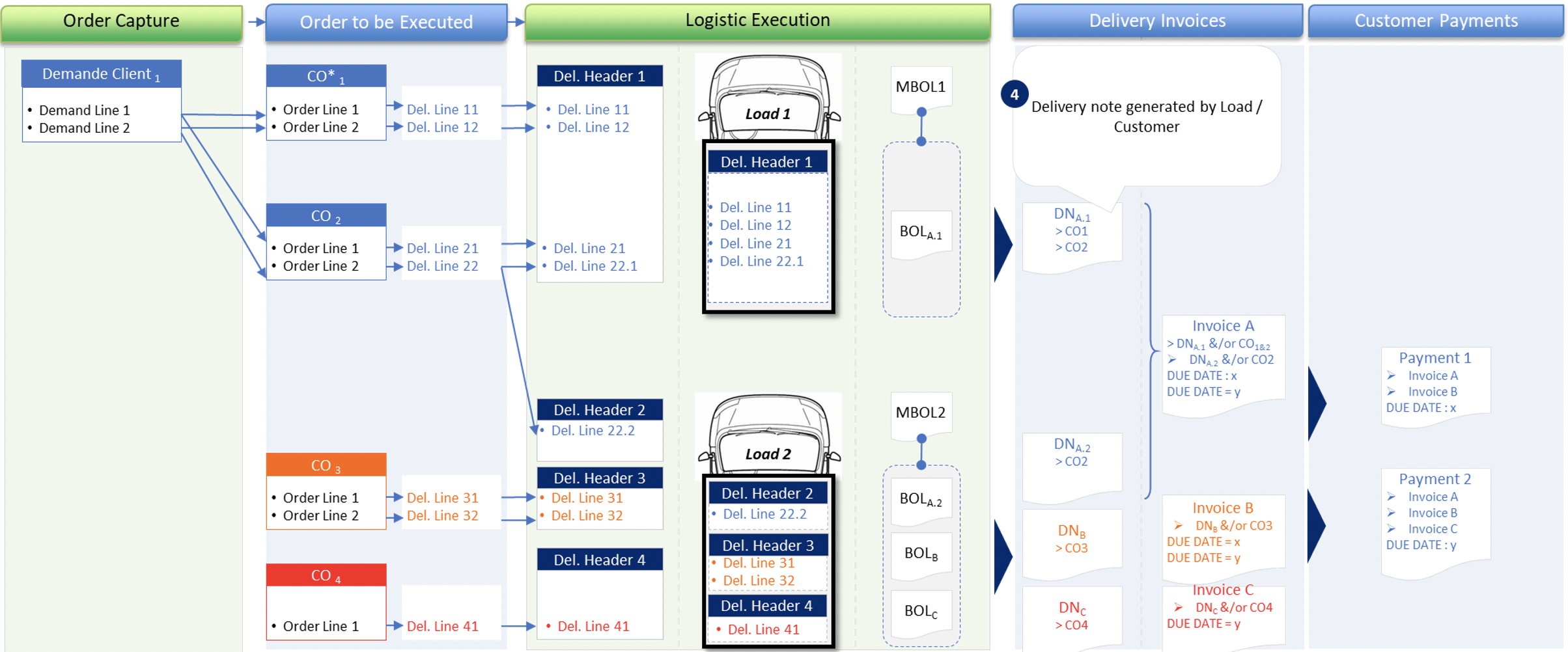
Ce travail sur la granularité et le langage omniprésent a permis d’identifier 3 sous-domaines : commandes client, livraisons client et factures client.
Nous avons aussi défini les dépendances entre sous-domaines (amont/aval), qualifiées à l’aide de patterns d’intégration stratégiques. Parmi les 9 patterns existants, nous en avons utilisé 4 : Conformist, Anti-Corruption Layer, Open Host Service et Event Published.
Le résultat : une context map combinant domain map et team map :
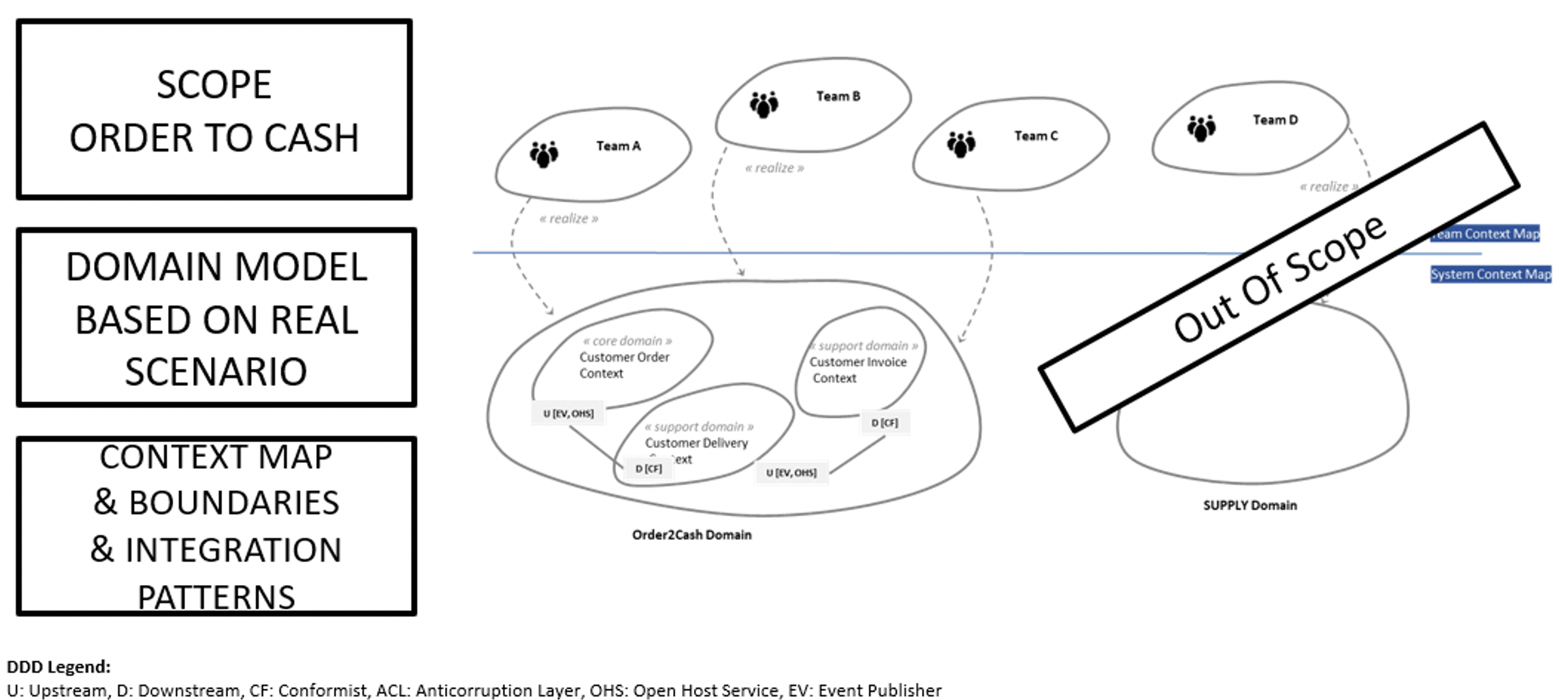
Ce mapping des équipes est utile pour détecter des incohérences, comme plusieurs équipes sur un même domaine — ce qui doit alerter.
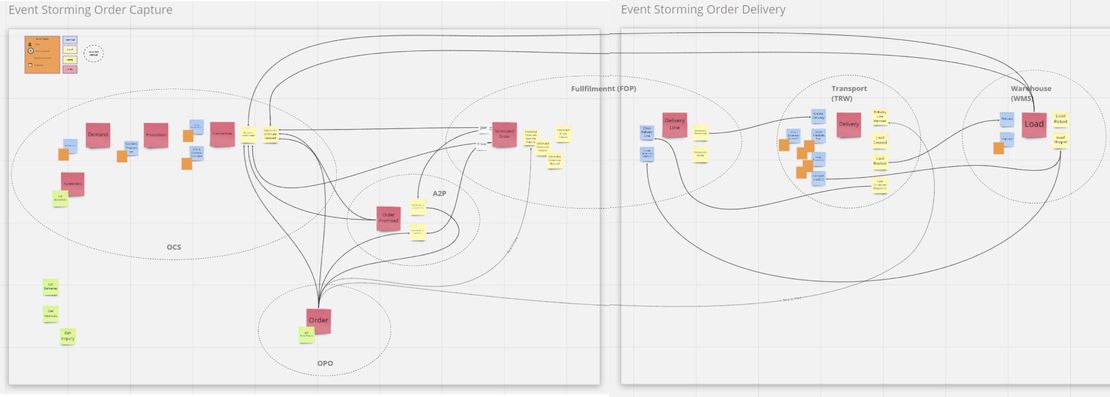
Mais attendez, vous parlez d’event storming, où sont les événements métiers ?
Effectivement, jusqu’ici nous avions surtout décrit les objets manipulés. Nous avons donc complété avec un véritable event storming, dont voici le résultat :

Les post-its rouges représentent les événements métiers majeurs. On y retrouve les sous-domaines « Commandes client » et « Livraisons client ». Les événements sont regroupés par application réceptrice.
Plongée dans l’implémentation technique
L’event storming métier décrit le domaine sans entrer dans les détails techniques. Pour aller plus loin, nous avons réalisé un event storming IT, utile pour :
- Identifier les données attendues par chaque solution ;
- Définir les besoins de stockage, d’exposition ou de consultation ;
- Identifier les APIs, événements, et flux.
Notre objectif était de bâtir une architecture orientée événements. Nous nous sommes appuyés sur Kafka, où les topics servent de conteneurs à ces événements.
La figure ci-dessous présente les topics utilisés :
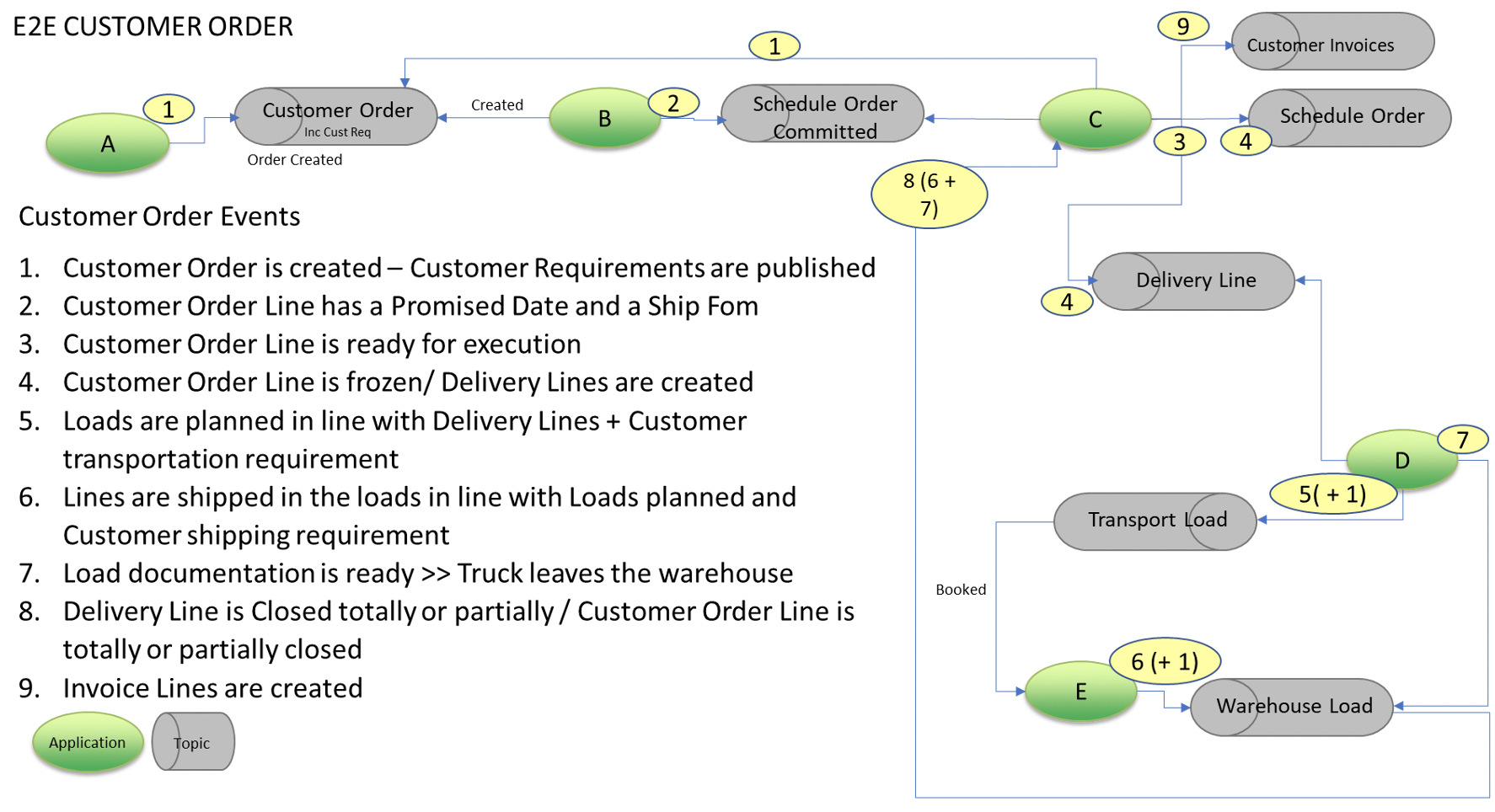
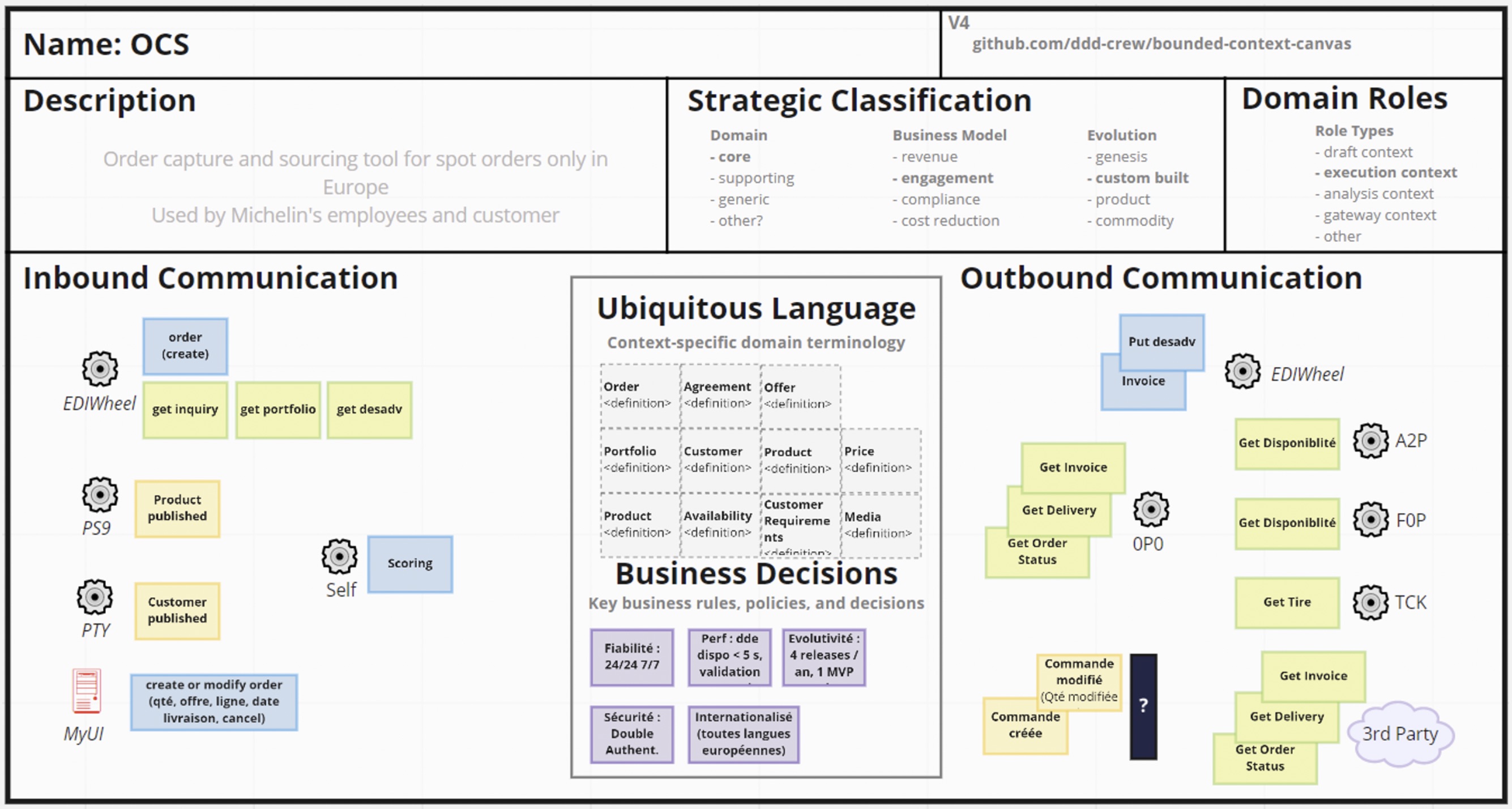
Dernière étape de notre démarche
Une fois les sous-domaines définis, il fallait décrire chaque bounded context avec précision : événements émis/reçus, APIs exposées/consommées, commandes exécutées.
Nous avons utilisé un canvas listant également :
- Les entités ou objets de valeur du domaine (dans le langage métier) ;
- Les règles métier et politiques gérées par ce contexte.
Exemple pour un contexte :