
Étude de cas Architecture for flow
- Olivier Jauze
- Case studies
- 1 mai 2023
Table des matières
Une étude de cas industrielle pour comprendre comment utiliser le Domain Driven Design et les Team Topologies pour concevoir une architecture orientée flux rapide.
Tout le monde a déjà entendu parler du Domain Driven Design et des Team Topologies. Le premier, popularisé par Eric Evans il y a plus d’une décennie, a connu un regain d’intérêt ces dernières années. Le second est le livre de référence de la décennie actuelle sur la manière d’organiser les équipes IT autour de 4 topologies principales et de 3 modes d’interaction. Cette étude de cas, inspirée d’un cas réel, propose une façon concrète d’appliquer simultanément le Domain Driven Design (DDD) et les Team Topologies pour parvenir à une architecture favorisant l’état de flux. Nous ne prétendons pas que cette approche est la seule possible, mais elle peut servir de guide utile.
Contexte
La connectivité ouvre de nouvelles perspectives pour améliorer les véhicules et les services de mobilité. Le réseau intelligent, les échanges de données constants et les solutions numériques globales bénéficient au transport et à la logistique à de multiples niveaux, en renforçant efficacité et durabilité environnementale. Le cas présenté ici concerne une plateforme de données conçue pour supporter les cas d’usage de mobilité connectée : prédiction de fin de vie des pneus, services de sécurité autour de la pression connectée, traçabilité des pneus, etc.

D’un point de vue flux de données, la plateforme :
- Ingère des données issues de capteurs IoT et de sources externes
- Les traite via des règles de qualité et enrichissement
- Produit des insights grâce à des capacités augmentées par l’IA, directement intégrés aux offres clients
- Expose des jeux de données et des APIs pour exploration et innovation continue
L’architecture technique repose principalement sur des services PaaS (Platform as a Service) soutenant les fonctions principales.
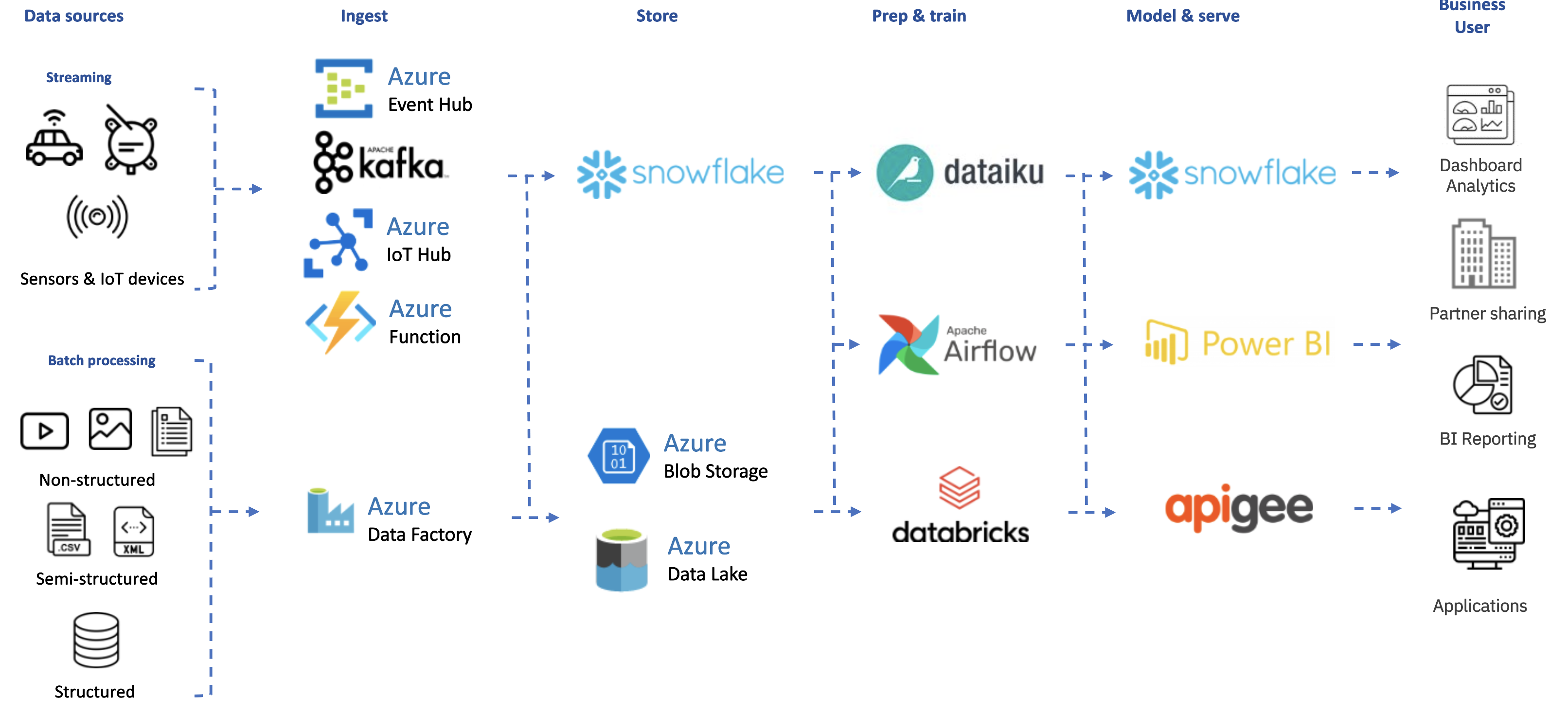
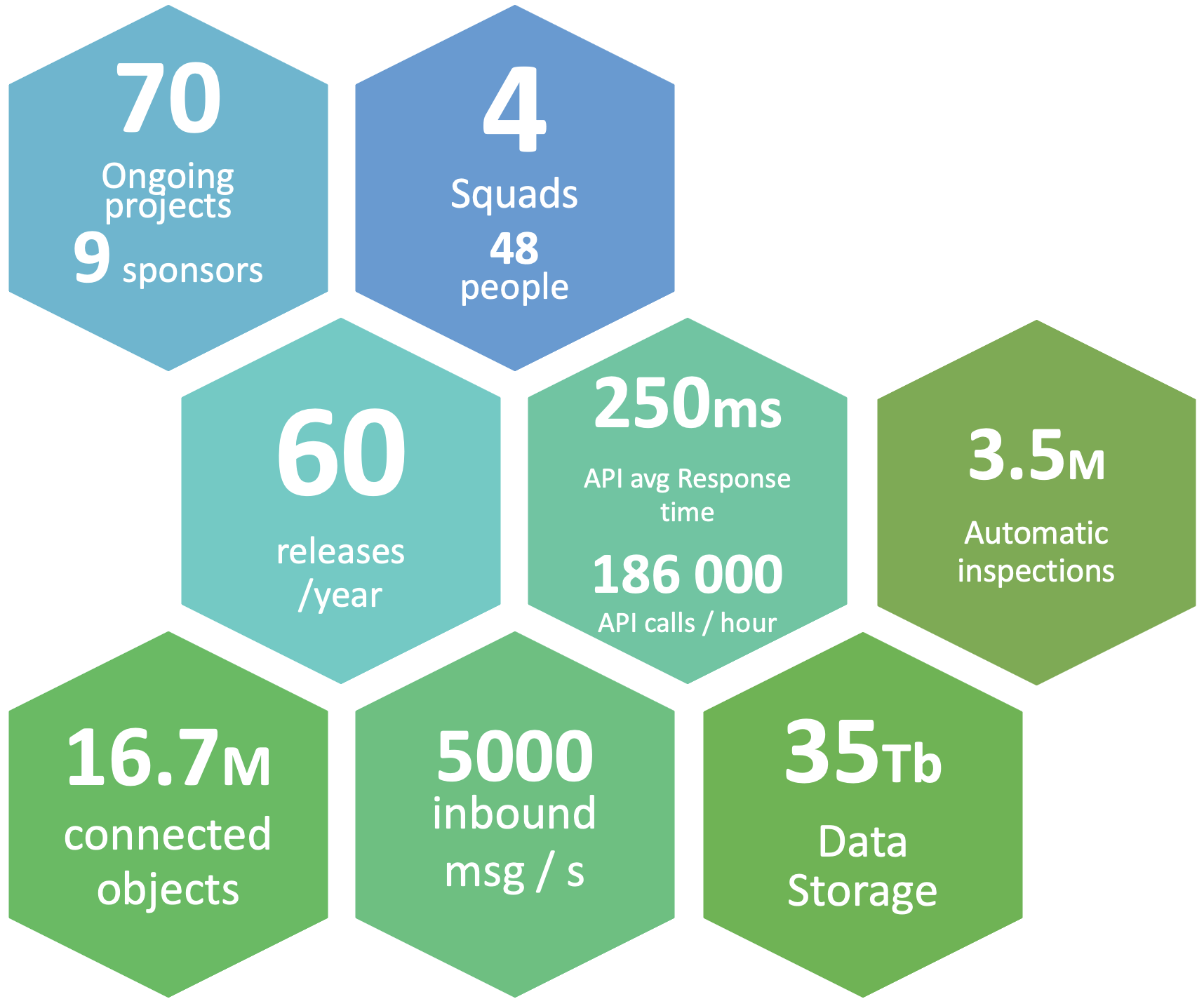
Les chiffres ci-dessous illustrent l’ampleur de cette initiative :
L’équipe en charge de cette plateforme était organisée autour d’une topologie bien définie : des équipes supposément alignées flux, collaborant sur un même produit (même dépôt Git), et une équipe système complexe gérant un composant spécifique.
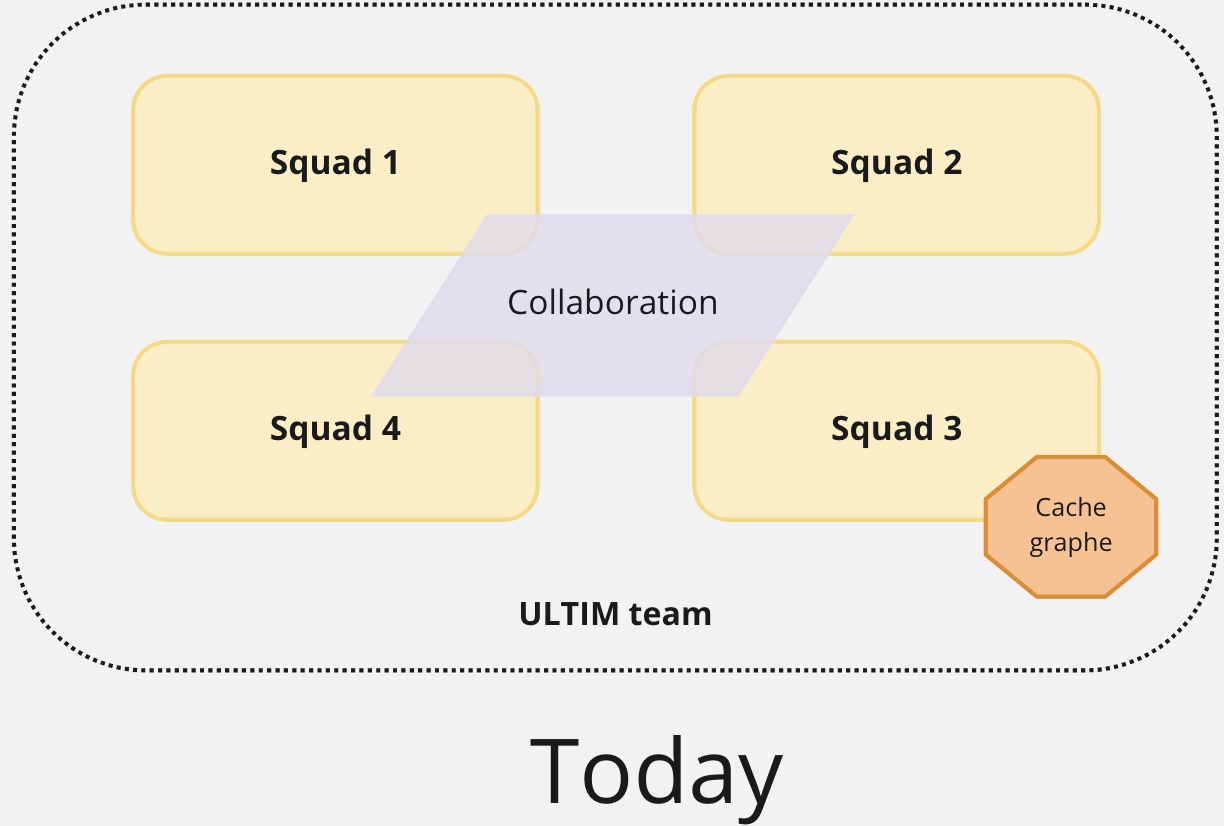
Cette équipe adopte dès le départ une logique produit avec l’état d’esprit “You Build It, You Run It”. Selon les métriques Accelerate (temps de cycle, fréquence de déploiement, MTTR, taux d’échec), elle est qualifiée de “performeur moyen” : 1,1 déploiement/semaine, 4 semaines de cycle, 4h de MTTR, 15% d’échecs.
Mais la performance se dégrade progressivement. Premier signe : le nombre d’éléments en cours dans le backlog grimpe à 51 (contre 3-4 en norme). Deuxième signe : le syndrome du “ce n’est pas dans mon périmètre”. L’équipe surchargée rejette les sujets, même ceux relevant de sa mission.
En un an, l’équipe passe de “moyenne” à “faible”. D’autres prennent le relais sur son périmètre.
Comprendre les problèmes
Des ateliers de diagnostic permettent d’identifier deux grandes catégories de problèmes :
Blocages du flux de valeur :
- 4 sous-équipes collaborant sur un même dépôt. Les sujets sont analysés par des rôles transverses avant d’être assignés, créant un goulot d’étranglement.
- Faible autonomie entre équipes : plus de 50% des sujets nécessitent plusieurs équipes.
- Le “train de releases” introduit des dépendances et ralentit.
Problèmes architecturaux et techniques :
- Malgré une architecture microservices, la plateforme est un monolithe avec 30 services partagés.
- Trop de technologies hétérogènes non maîtrisées (ex. : 7 bases de données).
- Certaines technologies choisies ont ajouté de la complexité au lieu d’en retirer.
L’organisation change sans aborder le fond. Il faut revoir l’ensemble pour scaler, sans nuire au flux.
Notre approche
Nous avons pris du recul pour adopter une vue systémique :
- Le temps est perdu en amont (grooming) et en aval (tests).
- Les équipes sont freinées par un manque d’autonomie.
Le toolkit Continuous Architecture offrait des outils pertinents. Le couplage et le monolithe masqué justifient l’approche DDD. Mais le DDD seul ne suffit pas : il faut aussi aligner les équipes selon les Team Topologies, conformément à la loi de Conway.
La combinaison DDD + Team Topologies permet une architecture modulaire alignée sur la chaîne de valeur et optimisée pour le flux. Elle facilite l’agilité business : création/suppression rapide d’équipes en fonction des sujets. Comme Amazon : “Plus on grandit, plus il est facile de croître.”
Event storming ou domaines de données ?
Le DDD commence souvent par un atelier Event Storming, mais ici ça ne collait pas : peu d’événements métiers communs, sujets trop variés.
Nous avons utilisé d’autres heuristiques : chaîne de valeur, SLA, utilisateurs finaux. Résultat : 4 domaines initiaux clairement identifiés (mines, algorithmes prédictifs, cycle de vie du pneu, logistique). Puis, d’autres se sont ajoutés (ex. : Mobility Assets, IoT, Datalake).
À l’issue de ces ateliers DDD, nous avions une cartographie claire des domaines, chacun avec ses utilisateurs, son owner, et ses offres.
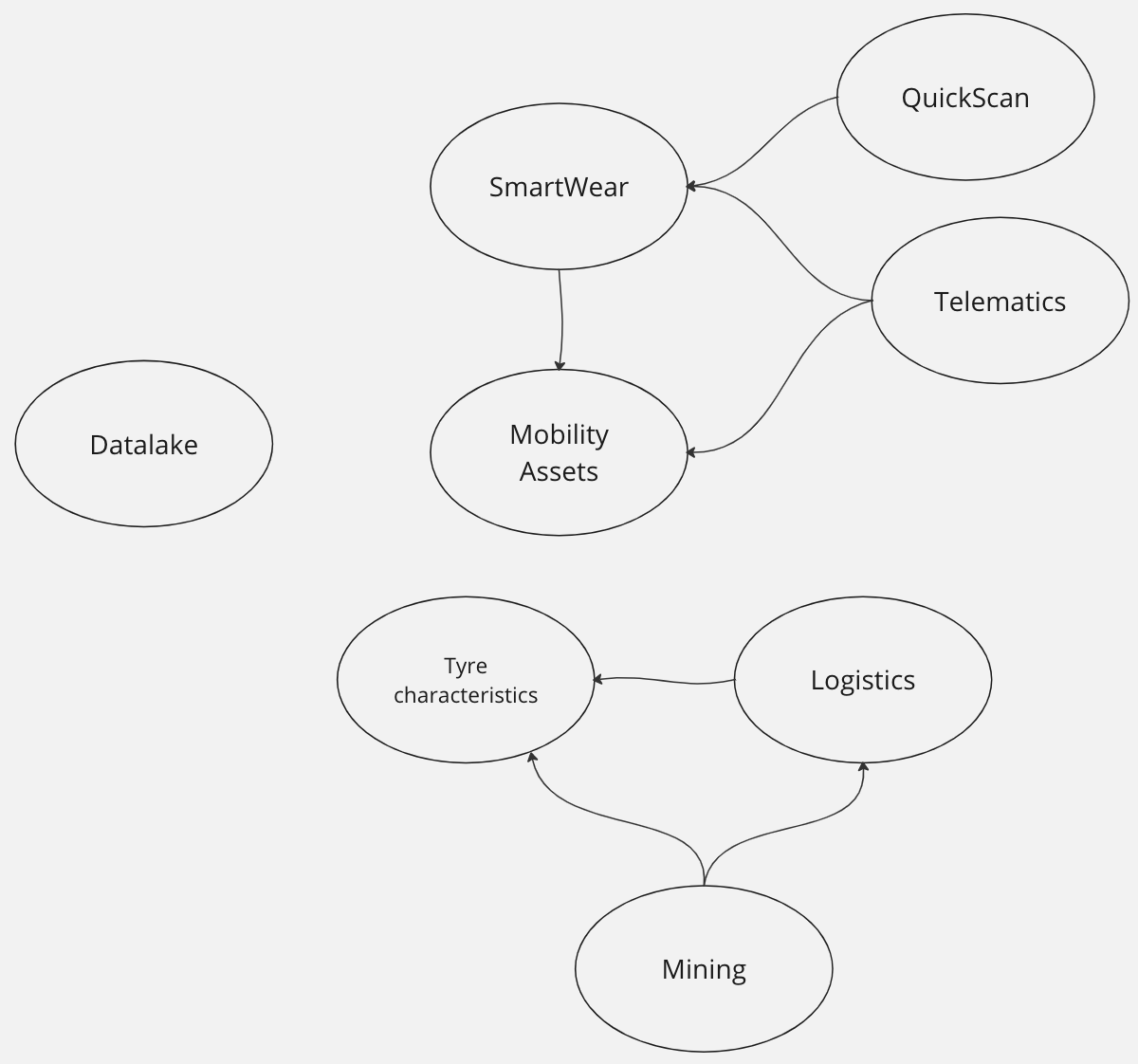
Team Topologies
Nous avons ensuite aligné l’organisation sur l’architecture, selon les 4 types d’équipes des Team Topologies :
- Stream-aligned teams sur les domaines métiers (ex. logistique, mines) et techniques (ex. datalake).
- Enabling team pour soutenir les stream-aligned teams sur les capacités techniques manquantes (pas encore prêtes pour une plateforme).
- Platform team dédiée à l’exposition du domaine “Mobility Assets” comme service interne clé pour tout l’écosystème.
- Complex sub-system team pour la Data Science, encore centralisée dans notre cas.
Voici le schéma cible :

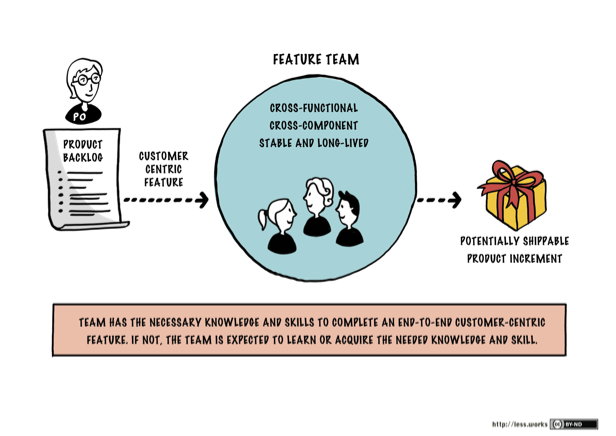
Principes clés pour les équipes
- Équipes de 4 à 8 personnes
- “You Build It, You Run It”
- Autonomie de déploiement
- Support assuré par l’équipe elle-même
- Responsabilité sur les données, notamment personnelles
- Ressources et charge de travail isolées
- Architecture documentée via ADR
- Maintien en condition opérationnelle
Un ADR par équipe
Chaque création d’équipe est précédée d’un Architecture Decision Record précisant :
- Périmètre fonctionnel
- Règles partagées de l’écosystème
- Stratégie d’extraction du monolithe
- Vue d’ensemble de l’architecture
Exemple : équipe Mobility Asset :
- Expose des référentiels externes (produits, véhicules, marques…)
- Gère les actifs (véhicules, pneus, boîtiers, conducteurs)
- Définit des clés d’identification
- Centralise les événements sans logique métier
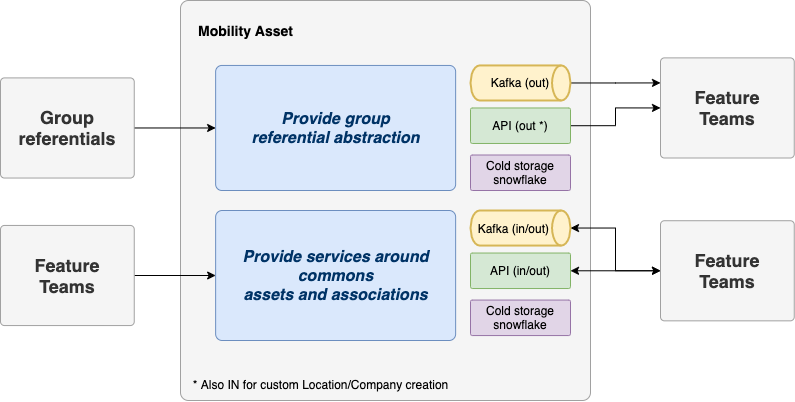
Stratégies d’intégration proposées :
- Utiliser Mobility Asset et accepter le SLA
- Gérer en propre et rétro-intégrer plus tard
- Faire une intégration temporaire avant passage à l’API de référence
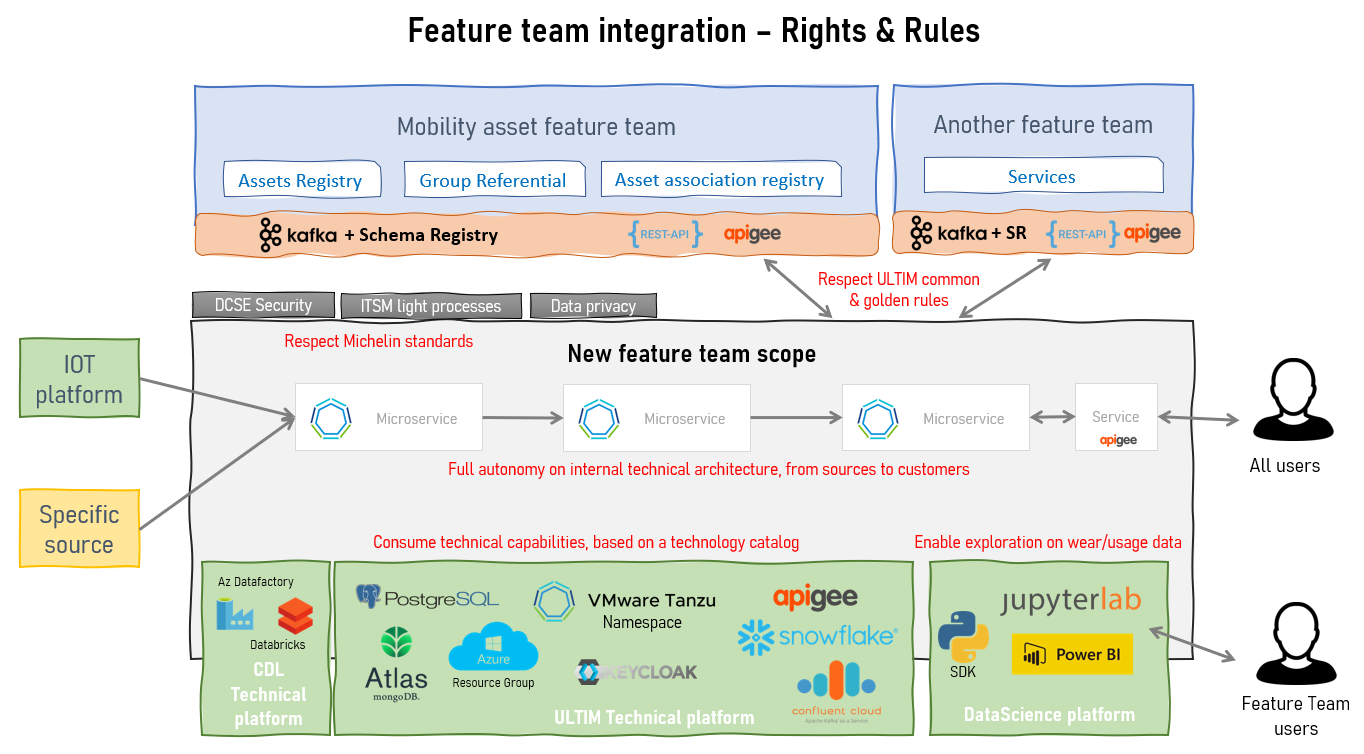
Est-ce que ça a marché ?
Oui, mais cela a pris 15 mois. Transformation progressive, une équipe après l’autre. Résultats :
- Autonomie accrue : disparition des trains de releases, déploiement libre, contrats API mieux formalisés.
- Charge cognitive réduite : moins de clients par équipe, plus de clarté et de focus.
- Support amélioré : “You Build It, You Run It”, meilleure qualité, meilleure réactivité.
- Équipes hybrides : mélange de profils techniques et métiers, une seule entité avec vision commune.
- Réduction des rôles transverses : les équipes sont responsables, les devops sont intégrés.
- Agilité business : possibilité de créer ou dissoudre rapidement une équipe selon les priorités du marché.
Sommes-nous arrivés au bout ?
Bien sûr que non. L’architecture est désormais modulaire et l’organisation alignée, mais le changement est permanent. De nouveaux sujets émergeront, d’autres disparaîtront. Grâce à l’approche Continuous Architecture, nous sommes prêts à nous adapter en continu.